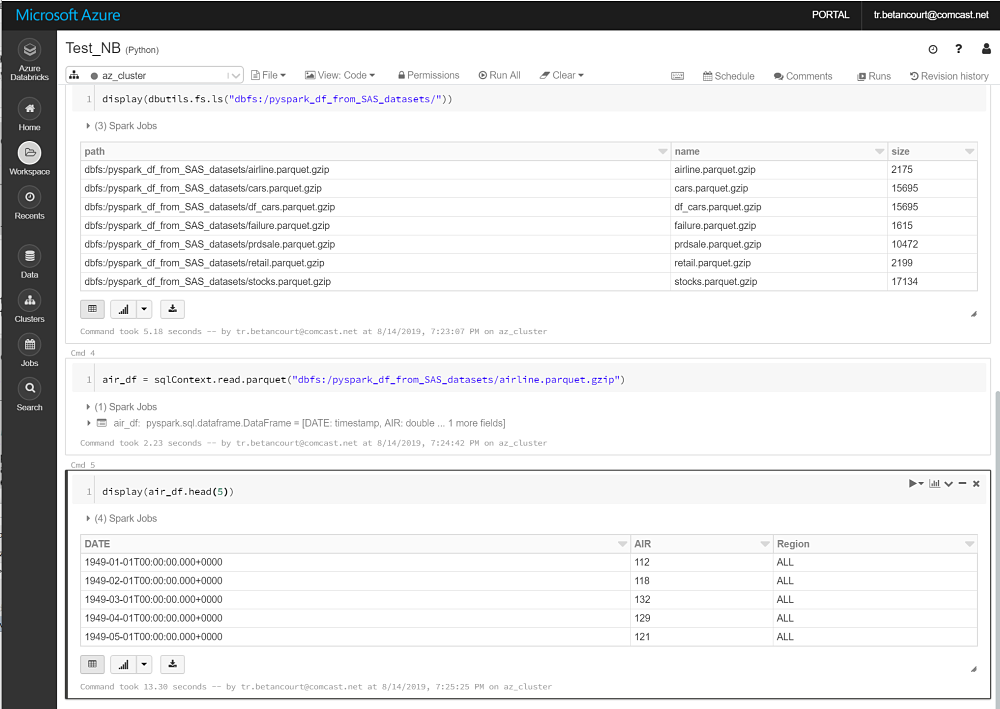
Introduction
Databricks diamonds Notebook
As part of the Dataricks Quick Start use Python to create the diamonds dataframe into a Delta Lake format.
Paste the url into a browser to see entire notebook.
https://databricks-prod-cloudfront.cloud.databricks.com/public/4027ec902e239c93eaaa8714f173bcfc/2503026962287721/974612617679297/3232646959701488/latest.html

Paste the url into a browser to see entire notebook.
Population vs Median Home Prices
https://databricks-prod-cloudfront.cloud.databricks.com/public/4027ec902e239c93eaaa8714f173bcfc/2503026962287721/3780363899802156/3232646959701488/latest.html
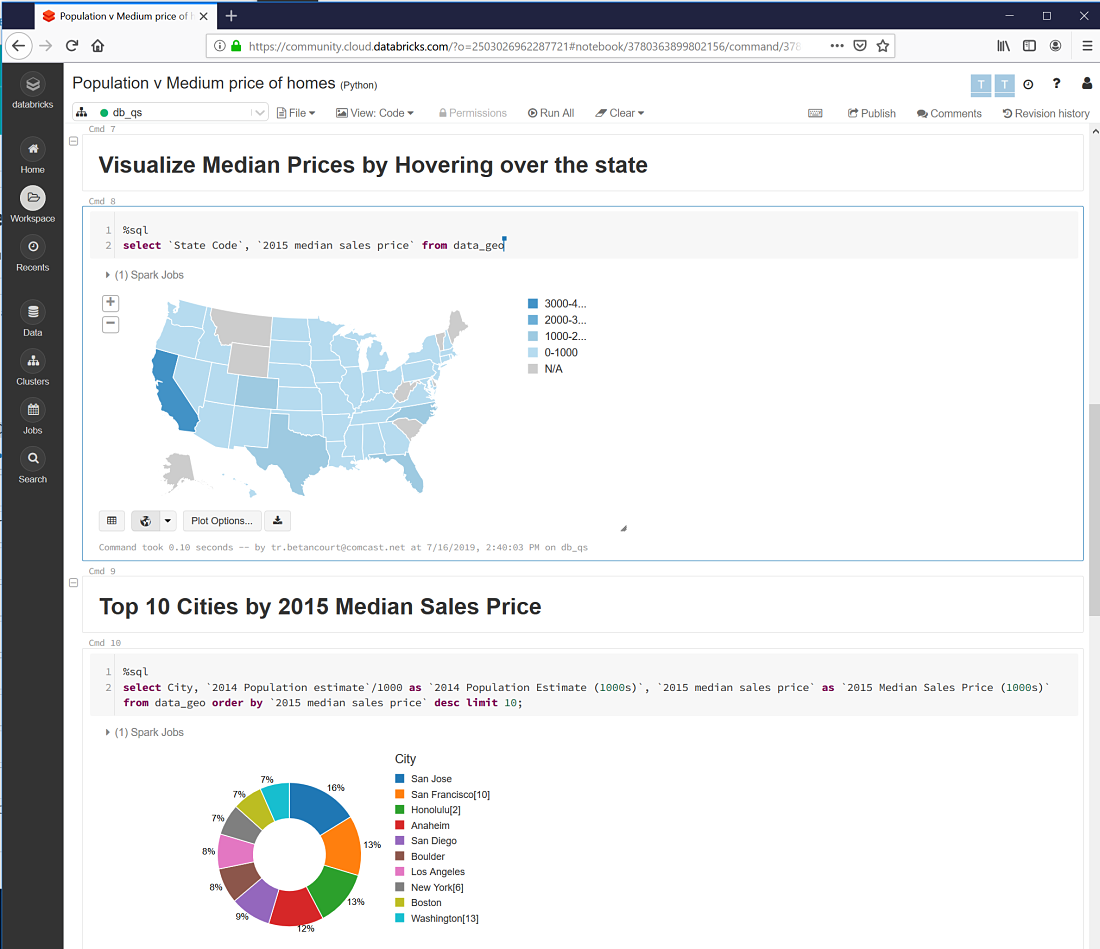
Paste the url into a browser to see entire notebook.
ML predicting Prices based on Population
https://databricks-prod-cloudfront.cloud.databricks.com/public/4027ec902e239c93eaaa8714f173bcfc/2503026962287721/3780363899802173/3232646959701488/latest.html

CLI Access
Generate a new token based on the instructions described here.
Install CLI.
pip install databricks-cli
Pass the token.
databricks configure --token
Databricks Host (should begin with https://): https://eastus.azuredatabricks.net/?o=XXXXXXXXXXX#
Token: dapiXXXXXXXXXXXXXXXXXXXX
Install Jq for JSON parsing.
wget -O jq https://github.com/stedolan/jq/releases/download/jq-1.6/jq-linux64
chmod +x ./jq
sudo cp jq /usr/bin
Call the Databricks CLI.
databricks workspace ls
Returns.
Users
Shared
Test_NB
Copy a local notebook to the Databricks workspace.
databricks workspace import_dir . /Users/tr.betancourt@comcast.net
Returns.
./Py_Spark_example1.ipynb -> /Users/tr.betancourt@comcast.net/Py_Spark_example1
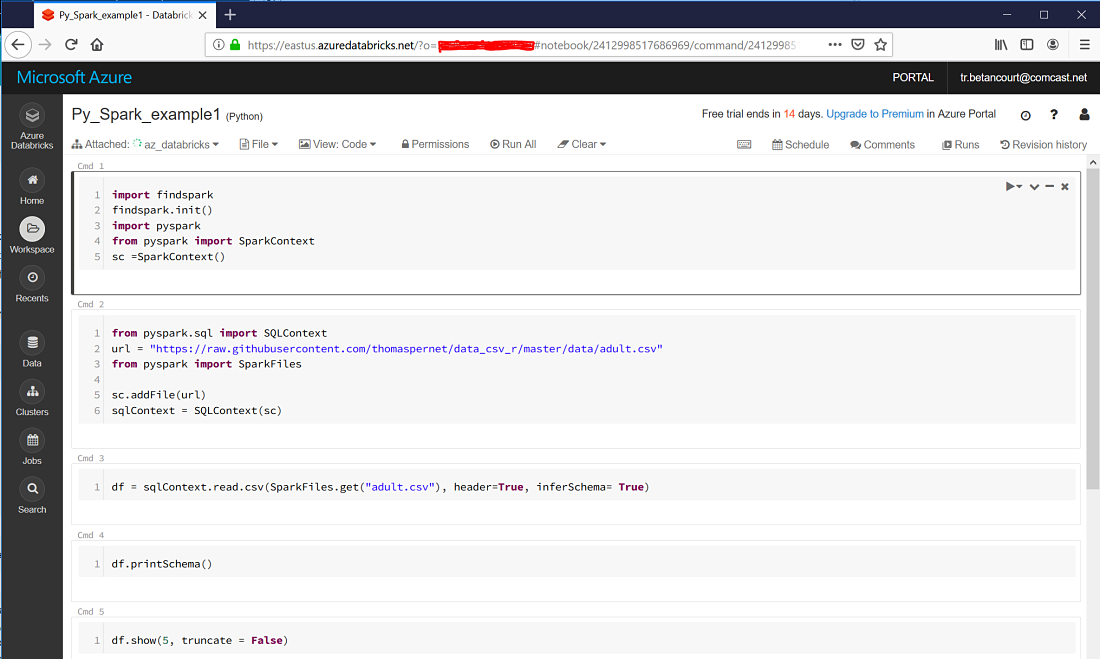
DBFS Access
Databricks exposes the DBFS API to enable Linux-like file I/O commands.
dbfs ls
Returns.
databricks-results
ml
tmp
Create a new directory on DBFS.
dbfs mkdirs dbfs:/pyspark_df_SAS_datasets
Validate.
dbfs ls
Returns.
databricks-results
ml
pyspark_df_from_SAS_datasets
raw_data
tmp
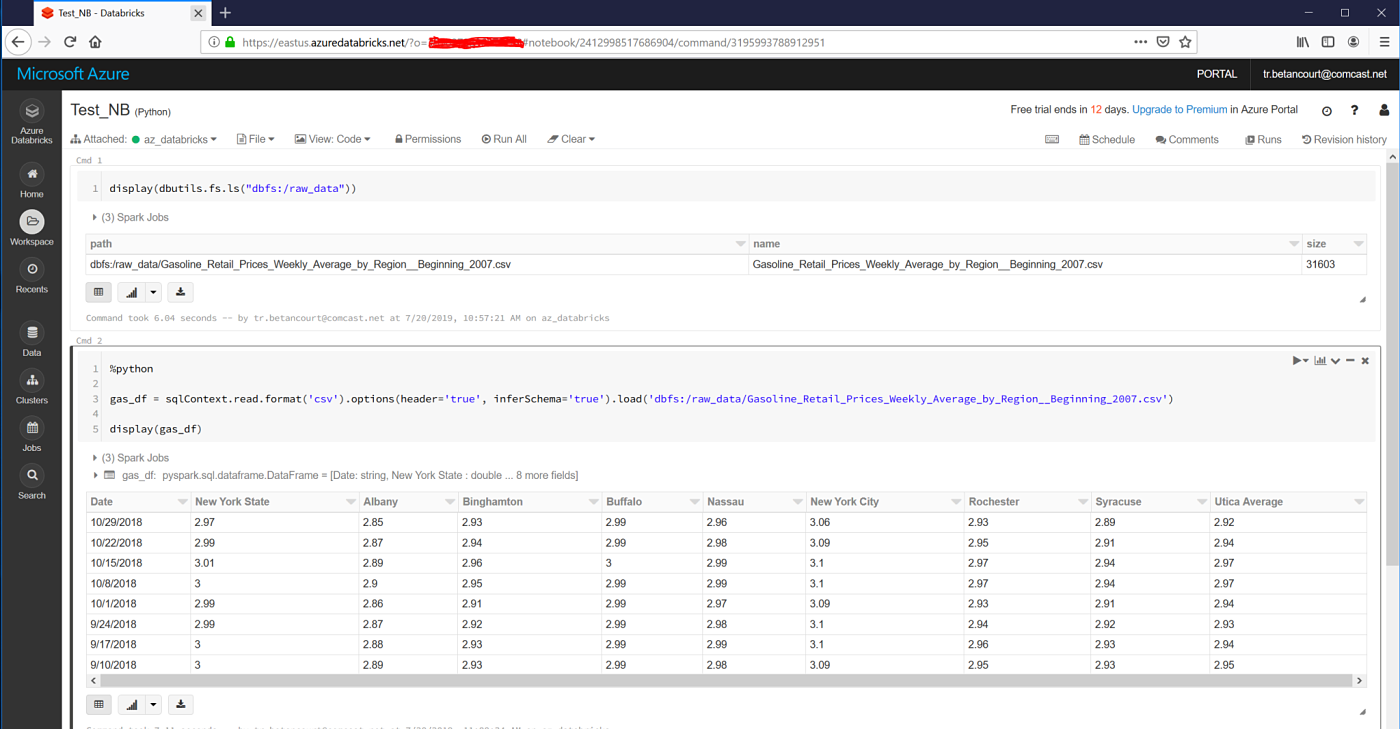
Copy local .csv file to DBFS.
dbfs cp ./Gasoline_Retail_Prices_Weekly_Average_by_Region__Beginning_2007.csv dbfs:/raw_data
Execute a databricks notebook and read uploaded .csv file.
SAS datasets -> PySpark Dataframes
Create the target output directory on remote DBFS file system.
dbfs mkdirs dbfs:/pyspark_df_from_SAS_datasets
On the local vm filesystem prepare the existing SAS datasets. Search the target path(s) and locate the input SAS datasets.
import os
import glob
from pathlib import Path
import saspy
import pandas as pd
Create the sas_datasets and df_name List. Recursively search the path for the names of SAS datasets (*.sas7bdat files).
p = Path('/home/trb/sasdata/export_2_df')
sas_datasets = []
df_names = []
sep = '.'
for i in p.rglob('*.sas7bdat'):
sas_datasets.append(i.name.split(sep,1)[0])
df_names.append('df_' + i.name.split(sep,1)[0])
Build the sd_2_df_dict Dictionary where the key is the output DataFrame name and the value is the first-level name of the input SAS dataset.
sd_2_df_dict = dict(zip(df_names, sas_datasets))
Start the SASPy Module to enable exporting SAS datasets to pandas DataFrames.
sas = saspy.SASsession(results='HTML')
Returns:
Using SAS Config named: default
SAS Connection established. Subprocess id is 11524
No encoding value provided. Will try to determine the correct encoding.
Setting encoding to utf_8 based upon the SAS session encoding value of utf-8.
Call SASPy's sas.submit() method and create a LIBNAME for the input SAS dataset. Assign the Libref string to the Python object libref for subsequent processing.
sas_code='''
%let libref = out_df;
data _null_;
libname &libref "~/sasdata/export_2_df/";
'''
libref_out = sas.submit(sas_code)
libref = sas.symget('libref')
Create the dfs Dictionary where the assigned DataFrame name is the key and values are the actual DataFrames. Each DataFrame is created by calling the sas.sasdata2dataframe() (using the sd2df alias) method by iterating over the sd_2_df_dict Dictionary which exports the SAS dataset into the target DataFrame.
dfs = dict()
for key, value in sd_2_df_dict.items():
sas_name = 'out_df.' + value
print('Exporting SAS Dataset:', sas_name, '==> DataFrame:', key )
df_name = 'df_' + value
#dfs[key] = key
dfs[df_name] = sas.sd2df(table = value, libref = libref, method='CSV')
Returns:
Exporting SAS Dataset: out_df.cars ==> DataFrame: df_cars
Exporting SAS Dataset: out_df.failure ==> DataFrame: df_failure
Exporting SAS Dataset: out_df.airline ==> DataFrame: df_airline
Exporting SAS Dataset: out_df.prdsale ==> DataFrame: df_prdsale
Exporting SAS Dataset: out_df.retail ==> DataFrame: df_retail
Exporting SAS Dataset: out_df.stocks ==> DataFrame: df_stocks
With the SAS datasets exported to DataFrames, call the <a href="https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.to_parquet.html"to_parquet method to write the DataFrame as a parquet file on the local filesystem. After the DataFrame written as a parquet file, call the dbfs cp command to copy the parquet file from the local file system to the the target dbfs:/pyspark_df_from_SAS_datasets/ location for Databricks.
for key, value in dfs.items():
# Export Dataframe to Parquet
pq_name = './' + key + '.parquet.gzip'
dfs[df_name].to_parquet(pq_name, engine='fastparquet', compression='gzip')
print('Exporting DataFrame:', df_name, '==> parquet file:', pq_name)
cmd = "dbfs cp " + pq_name + " dbfs:/pyspark_df_from_SAS_datasets/ --overwrite"
print('Copying:', pq_name, 'to Databricks')
os.system(cmd)
Returns:
Exporting DataFrame: df_stocks ==> parquet file: ./df_cars.parquet.gzip
Copying: ./df_cars.parquet.gzip to Databricks
Exporting DataFrame: df_stocks ==> parquet file: ./df_failure.parquet.gzip
Copying: ./df_failure.parquet.gzip to Databricks
Exporting DataFrame: df_stocks ==> parquet file: ./df_airline.parquet.gzip
Copying: ./df_airline.parquet.gzip to Databricks
Exporting DataFrame: df_stocks ==> parquet file: ./df_prdsale.parquet.gzip
Copying: ./df_prdsale.parquet.gzip to Databricks
Exporting DataFrame: df_stocks ==> parquet file: ./df_retail.parquet.gzip
Copying: ./df_retail.parquet.gzip to Databricks
Exporting DataFrame: df_stocks ==> parquet file: ./df_stocks.parquet.gzip
Copying: ./df_stocks.parquet.gzip to Databricks
Validate the parquet files are copied to dbfs:/pyspark_df_from_SAS_datasets/.
# Validate copy to Databricks
import subprocess
cmd = "dbfs ls dbfs:/pyspark_df_from_SAS_datasets/ > tmp"
results = subprocess.check_output(cmd, shell=True)
read = open("tmp")
print(read.read())
Returns:
df_airline.parquet.gzip
df_cars.parquet.gzip
df_failure.parquet.gzip
df_prdsale.parquet.gzip
df_retail.parquet.gzip
df_stocks.parquet.gzip
Initialize the Databricks cluster and read the exported SAS datasets.